���ϗʉ�͂�p��������
���� ���M
1. �͂��߂�
�@���{�̎Љ��w�̌����́A�傫���u�ψق̌����v�Ɓu�k�b�̌����v�̓�̕���ɂ킩���B�u�ψفv�Ɓu�k�b�v�͑Η�����T�O�ł͂Ȃ��B�������A�ψٌ����ł͒k�b���������Ƃ͏��Ȃ��ʓI�����������̂ɑ��āA�k�b�����͎��I���͂����S�Ȃ̂ŁA���ʂƂ��đΗ����Ă���Ƃ�����B�Ȃ��A���̂ق�����̐�����A���ꐭ��Ƃ������A���ꎩ�̂���舵�����������B
�@�{�e�ł́A�ψق̌����ɂ�����W�v���瑽�ϗʉ�͂܂ł̉ߒ��ɂ��āA�f�[�^�̗v��Ƃ����ϓ_����ȒP�ɉ������
2. �����f�[�^�̐����E�W�v
�@�S����S���E�̏W�c��ԗ�����������Ɨ͂Ŏ��{���邱�Ƃ͕s�\�ł���B���̂��ߎ��ۂ̐��̏W�c��Ώۂɂ��Ē����f�[�^�́A���ꂾ���ŋM�d�Ȏ����ƂȂ肤��B �@�������A�������������f�[�^���牼���̌��A�@���̔����A���m�̗v���̒T��������ɂ́A�f�[�^�̐������s���ł���B���ɗʓI���͂̏ꍇ�́A���l�I�ȏ��������邽�߁A���̐����̒i�K���d�v�ɂȂ�B
�@�����f�[�^�𐔗ʓI�ɏ�������Ӌ`�Ƃ��ẮA
- ���Ƃ̕��E���ۂɊւ���������ȒP�ɂ���
- ���肵����K����������
�Ȃǂ�����(�y��1999)�B�܂�f�[�^�̗v��ł���B���ʓI�ȃf�[�^�̏����͈ꌩ�q�ϓI�ȕ��͂ɂ݂��邪�A����͓��v�����̕��������ł���B���̂��߃f�[�^�̋L�q�͐��ʓI���͂ɓK����悤�ɕW�������Ă����K�v������B
�@�I�����̏ꍇ�A���l���͊ȒP�ł͂��邪�I�����쐬�ɒ��ӂ��K�v�ł���B�܂����R�̏ꍇ�̓J�e�S���[���Ƃɕ��ނ��邽�߂̈��̊���߂�K�v������B
�@�ł���{�I�ȃf�[�^�̗v��́A�P���W�v�A�N���X�W�v�Ȃǂł���B�����n��A�������Ƃɕ��ς⍇�v�A���U�Ȃǂ��v�Z���邾���ł��A�f�[�^�̂��܂��܂ȑ��ʂ��킩��B
3. ���ϗʉ�͂ɂ��v��
�@���������ڐ��̑��������f�[�^�ɂ����ẮA��{�I�ȏW�v�����ŌX����c������̂͗e�ՂłȂ��B��( �z�[���y�[�W )�ɂ��A�Q�ȏ�̕ϐ��̏ꍇ�A�N���X�W�v�̔�r�ł͑�ςł����ɗ��Ƃ��������邱�Ƃ��킩��B
�@�l�Ԃ̎v�l���ǂ����Ȃ��悤�ȕ��G�ȏ�v�铝�v��@�Ƃ��đ��ϗʉ�͂����݂���B���ϗʉ�͂͑�ʂ̃f�[�^�����\�I�ȌX���𒊏o���铝�v�I��@�ł���A�v�Z���@�͕��G�����A�R���s���[�^�̔��B�Ōl�ł��\�ɂȂ�قǕ��y���Ă����B
�@��\�I�ȑ��ϗʉ�͂Ƃ��ẮA
- �d��A���́@�������̕ϐ��Ɋ�Â��āA�ʂ̕ϐ���\������
- ���ʕ��́@�������̕ϐ��Ɋ�Â��āA�e�f�[�^���ǂ̌Q�ɏ������邩�肷��
- �听�����́@���ϗʃf�[�^�̎������C�����̑��������l�ɗv��
���q���́@�@���ϗʃf�[�^������ݓI�Ȃ������� ���ʈ��q�𐄒肷��
�Ȃǂ�����B�܂��AYes-No�^�̃f�[�^(�A���P�[�g�ɑ���)�̏ꍇ�A���{�ł͗ђm�ȕv�ɂ�鐔�ʉ����_���悭�p������B���ꂼ��T�ށA�U�ށA�V�ނ̖��������悻��L��(1)(2)(3)�ɑΉ����Ă���B
�@���发�Ƃ��ẮA�Α�(1992) ���͂��ߐ������̏o�ŕ�������B�C���^�[�l�b�g�ł́A�Q�n��w���؎��̃z�[���y�[�W(http://aoki2.si.gunma-u.ac.jp/)���ł��[�����Ă���B������玩�K�m�[�g�AWWW��ł̓��v�v�Z�T�[�r�X�Ȃǂ��s���Ă���A���ɕ֗��ł���B
4. �f�[�^�̗v���
�@�͐�(1981)�́A�w���{����n�}(LAJ)�x�ɂ�����W����`�̉Ґ���s���{���ʂɏW�v���邱�ƂŁA�W����`���ǂ̂悤�ȕ��z���݂��Ă��邩���l�@�����B����n�}�̃f�[�^�́A���₲�ƂɑS���e�n�̘b�҂��ǂ̂悤�Ȍ�`�����邩�Ƃ����`���ł���A���̂܂W�v���邱�Ƃ͂ł��Ȃ��B���̂��߁A
- �W����`�̂ݑΏۂ��i��
- �W����`�ɋ߂����̌���܂Ƃ߂�
- �n���s���{���P�ʂŏW�v����
�Ƃ������悤�ɁA�ړI���߂Đ��ʓI�ɂ܂Ƃ߂������邱�ƂŁALAJ�̃f�[�^�𐔗ʓI�ȕ��͂��\�ȃf�[�^�ɂ���ς���(���})�B
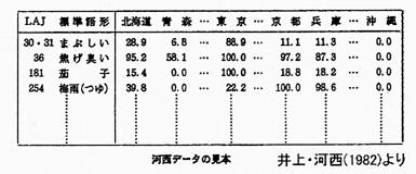
�@���̏�Ԃł����f�[�^�͂��Ȃ�v�ꂽ��ԂɂȂ����B���悻�̕W����̕��z�X���͂��邱�Ƃ͏o����B���̕\�͏W�v�ΏۂƂȂ���82��`�̓s���{���ʕW����`���̕��ςł���B�֓��A���Ƃ������n�悪�W����̊�b�ɂȂ��Ă��邱�Ƃ��킩��B

�@��������q�����悤�ɁA�s���{���ʕW����`����82���ڕ��߂邾���ł́A�Ȃ��Ȃ��W���c�����Â炢�B���̂��ߔw��̗v���͂��鑽�ϗʉ�͂ւƔ��W�������̂����E�͐�(1982)�ł���B
�@���̘_���ł́A82���ځ~48�n��(�s���{��+�������ו�)�̕W����`���̍s����A���ϗʉ�͂ł�����q���͂ɂ���ĕ��͂��A�W����`���A�n�悲�ƌ�`���ƂɃp�^�[�����ނ��čl�@���Ă���i���}�\�j�B
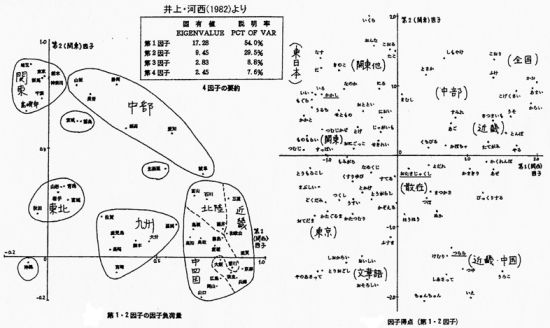
�@�͐��̃f�[�^�� LAJ �̈ꑤ�ʂɂ����Ȃ����A���̊�ɂ��������ĊȌ��ɐ��l�����ꂽ���߂ɁA���ϗʉ�͂ɂ��K�����f�[�^�ɂȂ����Ƃ�����B�����đ��ϗʉ�͂ɂ���āA���G������
LAJ �f�[�^���A�W����`�Ƃ������_����v�o�����̂ł���B
5. ������
�@�����f�[�^�͐��ʓI�ɗv�邱�Ƃł��[�����͂��\�ɂ���B���������̈���Ő��ʓI�����ᔻ�ɂ����Ȃ����Ƃ͊댯�ł���B��ȗ��R�Ƃ��āA
- �v�Z�̂��ƂɂȂ鐔�l�́A�o����m�����瓱���o��
�i���l���ŏ����瑶�݂��Ă���̂ł͂Ȃ��j - ���ʓI���͂̌��ʂ͑ΏۂƂȂ�w��I�ɂ͉��̈Ӗ����Ȃ�
�i�������͉̂�����炸�A�l�@�E���߂��s���j
�Ȃǂ�����B���v�̖��_�𗝉����Ă��Ȃ��ƕ��͂���邨���ꂪ������B���ɑ��ϗʉ�͂̏ꍇ�A�v�Z�������G�Ȃ��߁A���Ȍn�̐l�X�̑命�����v�Z�ߒ��𗝉������ɕ��͂Ɏg�p���Ă��蒍�ӂ��K�v�ł���B�����ƊȒP�ȓ��v��p����ۂł��A������x�͌����𗝉����Ă����i�����ł���Ή�����Ȃǂɂ�����Ă��錴���̃C���[�W�ɂ���Ă����j�̂͏d�v�Ȃ��Ƃł���B
�Q�l����
�� �ɐL (�����X�V)�wBlack Box�x(WWW��̃f�[�^��̓c�[��)
�@http://aoki2.si.gunma-u.ac.jp/BlackBox/BlackBox.html
�Α� ��v (1992)�w�����킩�鑽�ϗʉ�́x�����}��
��� �j�Y�E�͐� �G���q(1982)�u�W����`�̒n���I���z�p�^�[���v����w131
�y�� ���� (1999)�u�����ōl���A�����ʼn����l���Ȋw�\���ʓI���͂̂����߁\�v�l���w�Ə��20 �א��o��
�͐� �G���q(1981)�u�W����`�̑S�����z�v���ꐶ��354
����w�E�����w�ɂ�����f�[�^���������@�i�����ꕔ�݂̂ł����j
[�A���P�[�g�����E���v����]
���� �j�j(1994)�w�A���P�[�g�������͗p�\�t�g�E�F�A GLAPS�̎g���� ��2�Łx(���Ɣ�)
[�����E���͕��@]
���� �@���E�^�c �M��(1991)�w�V�E�����w���w�Ԑl�̂��߂Ɂx���E�v�z��
�{�n �T�E�b�� �r�N�E�쑺 �돺�E����j�j �� (1997) �w�n���h�u�b�N �_���E���|�[�g�̏������x�������@
[����n�}]
���� ���q�E���� �S�� (2001)�w�p�\�R���ɂ�錾��n���w�F���̕��@�Ǝ��H SEAL���[�U�[�Y�}�j���A���@��T�Ł@(SEAL version 6.0
for Windows98/Me/2000)�x�����ȉȊw�������
��SEAL �ɂ��ẮAhttp://www.nicol.ac.jp/~fukusima/inet/lg.html
�ɂČ��J���Ă���B
[����W]
DB-West(�����{���ꍑ���w�f�[�^�x�[�X������) �Ғ� (1995) �w�p�\�R�����ꍑ���w�x�[����
�^�c �M���E�_�j�G�� �����O (1997)�w�Љ��w�}�W�\���{��E�p�����\�x�H�R���X